Note: This content was originally published at the Simple AWS newsletter.
Imagine this scenario: You have some data that's absolutely critical to your business. If you lose it, it's a disaster! How do you recover?
Data Loss Scenarios
First, we need to define what we mean when we say "lose it". How do you lose data? Let's consider some scenarios, and what we can do to in each case.
Data Loss Because of Hardware Failure
As I'm sure you know, computer hardware is sensitive equipment, which will inevitably fail at some point. When working with AWS we don't really see or manage the hardware, but we're still vulnerable to hardware failing. That's why AWS services publicly advertise their durability: EBS has 99.9% or 99.999% depending on volume type, while S3 has 99.999999999% (referred to as 11 nines, or 11 9s). 99.999999999% (11 nines) durability means that if you store 10 million objects, then you expect to lose an object of your data every 10,000 years.
How to prevent it
S3 should be more than enough to protect from bit rot or simultaneous hardware failures. If you're not storing your critical data in S3, start at least backing it up there. You can create Snapshots from EBS volumes or RDS instances, which are stored in S3.
Data Loss Because of Human Error
This includes scenarios where you or anyone on your team (with legitimate access and good intentions) accidentally deletes or overwrites data. In S3, it can be deleting an object or an entire bucket. In EBS, EFS or anything mounted in the file system, it can be a typo when running a command like rm -rf. In a database, it's more often than not a query ran with the wrong parameters, such as a SQL UPDATE with no WHERE clause.
Automated processes are also included in this scenario, since the reason they might delete or overwrite data that they shouldn't have touched is always due to human error when programming or configuring them.
How to prevent it
The first step is to understand that anyone can make a mistake, no matter how skilled or careful. Training and clearly defined procedures will reduce the probability of mistakes, but they'll never take it to 0. Limiting accesses and implementing guardrails and additional confirmations will further reduce the probability.
Overall, the best way to protect from this is to have backups of the data that can't be overwritten or deleted through the same means. For example, you can copy database snapshots to another AWS account.
Data Loss Because of Hacks or Ransomware
In this case, you're dealing with a malicious actor intentionally trying to delete the data, or make it inaccessible to you. The most common scenarios are Ransomware attacks, where an attacker either steals or encrypts the data, and asks you for money in exchange for granting you access to it.
Attackers gain the ability to affect your data in AWS through credentials. This can be your own username and password stolen, the IAM role of an EC2 instance that the attacker gained access to, or any other way that they can gain AWS credentials to your account.
How to prevent it
Basic security measures such as security best practices for AWS accounts, minimum privileges, and application security go a long way. Requiring Multi-Factor Authentication for certain AWS operations, such as deleting objects in S3, is another good measure.
What can happen is that an attacker gains some form of access, often not enough to compromise the entire AWS account or access your data, and then performs lateral movements and privilege escalations to gradually gain more access. A really simple example would be an EC2 instance with no access to S3 but an IAM Policy that grants permissions iam:*. An attacker with access to that instance can't immediately encrypt an S3 bucket, but they can use that instance's credentials to create a new IAM User for themselves, which has access to S3.
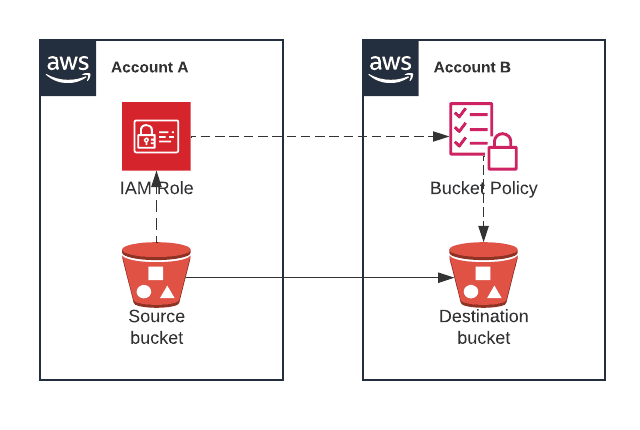
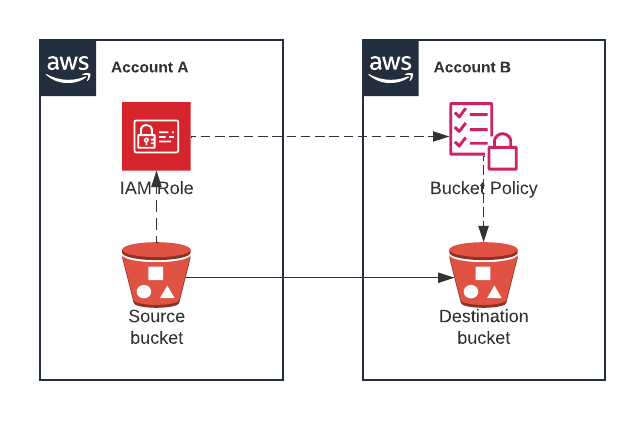
A way to protect against that is to store backups of data where they can't be tampered with from the same place where the data is. A good example, which I'll show you how to configure, is to set up a separate AWS account (let's call it Account B) and replicate there all objects in an S3 bucket. So long as there's no way to delete those objects in Account B from Account A, there's no path for an attacker with access to Account A to delete or encrypt the data in Account B. This doesn't completely eliminate the risk! But it makes it much less likely to occur, since an attacker would need to succeed at two separate attacks, one to gain access to Account A and one to Account B. This, coupled with ways to detect failed sign in attempts to AWS, significantly improves your security.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
Disaster Recovery Metrics: RPO and RTO
Before we move on to the solution, there's two things I want to discuss briefly, which will determine how often you perform your backups and what backup strategies and/or technologies you can use. They're two of the most common Disaster Recovery metrics:
Recovery Point Objective (RPO)
This is a measure of how much time can pass from when data is written to when it's backed up. It's measured in time units, usually in hours or minutes. Any data that was written less than "RPO" ago isn't guaranteed to be backed up, and in the event of a disaster it wouldn't be found in the backups, and would be lost.
For example, an RPO of 12 hours means any data that was written less than 12 hours ago isn't guaranteed to be backed up. A typical way to implement an RPO of 12 hours is to create backups twice a day, for example at 00:00 and 12:00. Data isn't guaranteed to not be backed up either, for example a disaster occurs at 13:00 the only data lost would be from the previous hour, which is the time since the last backup.
The reason RPO isn't exactly equivalent to time between backups is because backups can also be implemented in a continuous or nearly continuous way. For our backup every 12 hours example we're assuming the backup is instantaneous, which isn't exactly true but it's a good approximation. If we run backups every 1 minute, then the 30 seconds that the backup process might last isn't a number we can ignore, and our RPO would be 1 minute and 30 seconds.
The duration of the backup process is sometimes called replication delay. For example, Aurora has a replication delay of 1 minute between the primary instance and its replicas. That gives a Disaster Recovery strategy of using an Aurora replica a 1-minute RPO, since the replication process is started nearly immediately when data is changed.
Different data can have different RPOs. For example, data stored in S3 can have an RPO of 1 hour, and data on RDS an RPO of 6 hours. That's perfectly normal, and you should consider how bad it would be to lose all new data from the last X time to decide whether you're good with your numbers or need to improve them. RPO can be heavily constrained by the technology used to store the data and the technologies and techniques used to back it up. For example, an RPO of 1 hour is normal for S3 because the easiest backup method to set up for S3 is Cross-Region Replication, a feature already built into S3 with an RPO of 1 hour (15 minutes if you enable Replication Time Control).
Recovery Time Objective (RTO)
This is the target time between when you detect that a failure is happening and when you have the backup live and serving traffic at the same quality of service as if there was no failure. It's measured in time units, usually minutes or hours.
For example, if you're backing up your RDS database with RDS Snapshots, your RTO is going to be more or less the time it takes you to create a new RDS instance from the snapshot (usually between 30 minutes and 2 hours, depending on the size of the snapshot).
More accurately, your RTO would be the time between when you detect a failure in the original RDS instance and when the new RDS instance created from the snapshot is serving traffic. If you've automated this process, 99% of the recovery time is going to be creating the RDS instance. If you haven't, you need to take into account the time it takes you to:
Receive an alert
View that alert
Log in to the system
Find the correct snapshot
Figure out the correct configurations for the new RDS instance
Launch the creation of a new RDS instance
Switch over traffic to the new RDS instance
Every part of that which you can automate will reduce your RTO, and also reduce the chance that you make a mistake and, for example, restore the incorrect snapshot, or create the new RDS instance in the wrong VPC. Automate whatever you can (you can automate all of that). Start with the longest sentences, I wrote them like that on purpose.
Disaster Recovery in AWS
In AWS jargon, Disaster Recovery means being able to get the entire system back online in the case of an AWS Region failing. For that, you'll need to have the data available in that other region, as well as any additional resources required to access the data, such as the KMS key used to encrypt it (remember that KMS keys are regional by default, and you can create multi-region keys).
Getting the entire system back online also requires you to stand up compute capacity (be it EC2 instances, an ECS on Fargate cluster, Lambda functions, etc), make the data accessible (e.g. launch an RDS instance from the copied RDS snapshot), and switch over traffic. It's a complex process, there are different strategies, and there are multiple things to take into account depending on your RTO and RPO.
The next post is going to be about Disaster Recovery strategies, and being prepared to deploy the entire system in another AWS region. The first step towards that is to have the data accessible, so let's focus on that.
Let's view a solution to back up data in S3 to another S3 bucket in a different AWS account. To better protect from different disaster scenarios, you should make sure access to this other AWS account is very restricted.
Step 0: Preparation
Log in to an AWS account, let's call it Account A.
Open the S3 console
Click Create bucket
Enter a name for the source bucket (must be unique across all AWS)
Scroll down to Bucket Versioning and select Enable
Click Create
Copy or write down the Account ID of Account A (you'll need it later)
Log in to a different AWS account, let's call it Account B
Open the S3 console
Click Create bucket
Enter a name for the destination bucket (must be unique across all AWS). Write down the name.
Scroll down to Bucket Versioning and select Enable
Click Create
Copy or write down the Account ID of Account B (you'll need it later)
Step 1: Enable Replication in the Source Bucket
Log back in to Account A and go to S3
Click on the source bucket (the one you created on Step 0)
Click the Management tab
Scroll down to Replication rules and click Create replication rule
Under Replication rule name enter a name for the rule, such as cross-account replication
Under Choose a rule scope, select Apply to all objects in the bucket
In the Destination section, under Destination select Specify a bucket in another account
Under Account ID enter the Account ID of Account B (where the destination bucket is)
Under Bucket name, enter the name of the destination bucket
Check Change object ownership to destination bucket owner
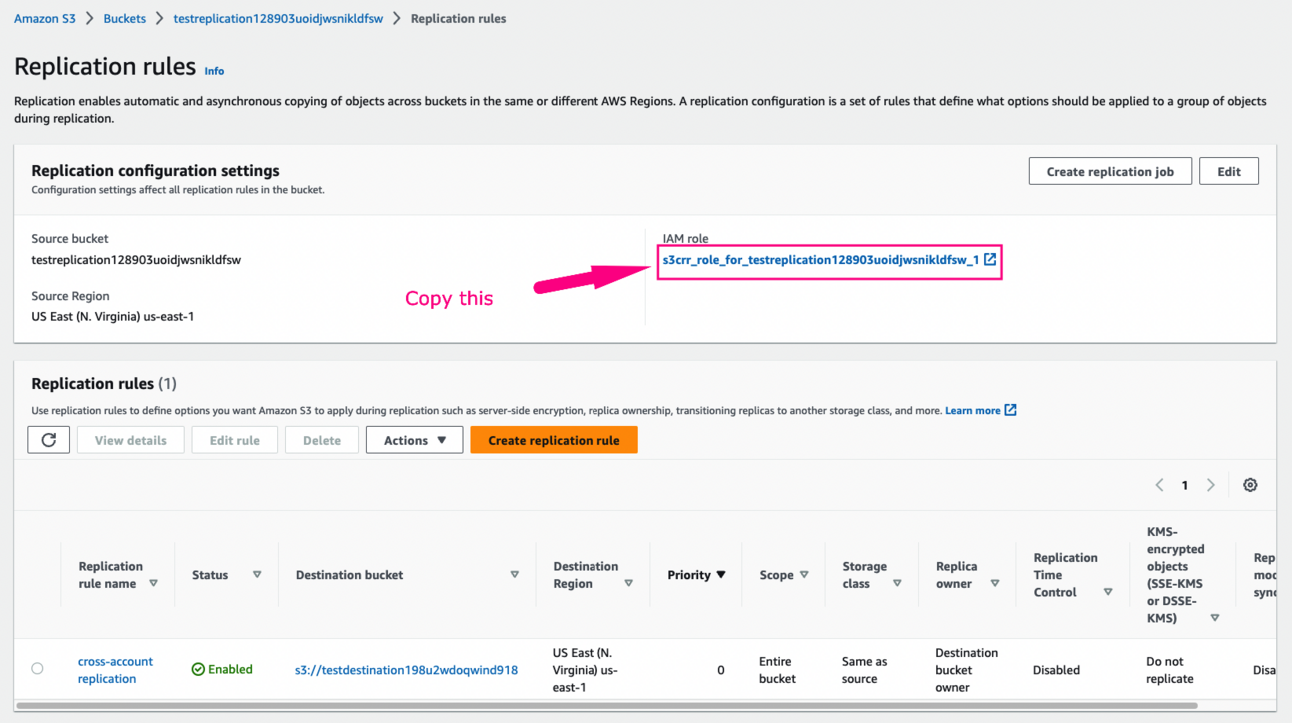
In the IAM role section, under IAM role open the dropdown and select Create new role
Click Save
Click Submit (we don't have any existing objects, so what we choose here doesn't really matter)
In the Replication configuration settings section, under IAM role, copy the name of the IAM role that was created automatically
Step 2: Update the Policy on the Destination Bucket
Log in to Account B and go to S3
Click on the destination bucket (the one you created on Step 0)
Click the Permissions tab
Next to Bucket policy, click Edit
In the following policy, replace ID_OF_ACCOUNT_A with the ID of the account where the source bucket is, NAME_OF_THE_IAM_ROLE with the last value you copied in Step 1, and NAME_OF_THE_DESTINATION_BUCKET with the name of the destination bucket. Then click Save.
{
"Version":"2012-10-17",
"Id":"",
"Statement":[
{
"Sid":"Set-permissions-for-objects",
"Effect":"Allow",
"Principal":{
"AWS":"arn:aws:iam::ID_OF_ACCOUNT_A:role/service-role/NAME_OF_THE_IAM_ROLE"
},
"Action":["s3:ReplicateObject", "s3:ReplicateDelete"],
"Resource":"arn:aws:s3:::NAME_OF_THE_DESTINATION_BUCKET/*"
},
{
"Sid":"Set permissions on bucket",
"Effect":"Allow",
"Principal":{
"AWS":"arn:aws:iam::ID_OF_ACCOUNT_A:role/service-role/NAME_OF_THE_IAM_ROLE"
},
"Action":["s3:List*", "s3:GetBucketVersioning", "s3:PutBucketVersioning"],
"Resource":"arn:aws:s3:::NAME_OF_THE_DESTINATION_BUCKET"
}
]
}
Step 3: Upload an Object to the Source Bucket
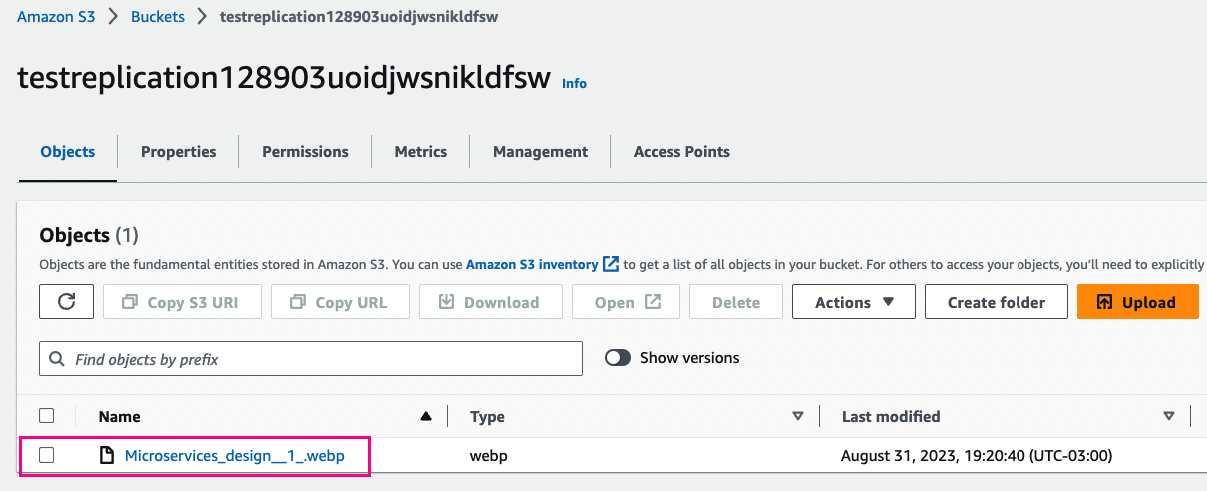
Log back in to Account A and go to S3
Click on the source bucket
Click Upload
Click Add files, select one or more files, and click Open
Click Upload
Verify that the file is uploaded to the Source bucket
Step 4: Upload an Object to the Source Bucket
Log back in to Account B and go to S3
Click on the destination bucket
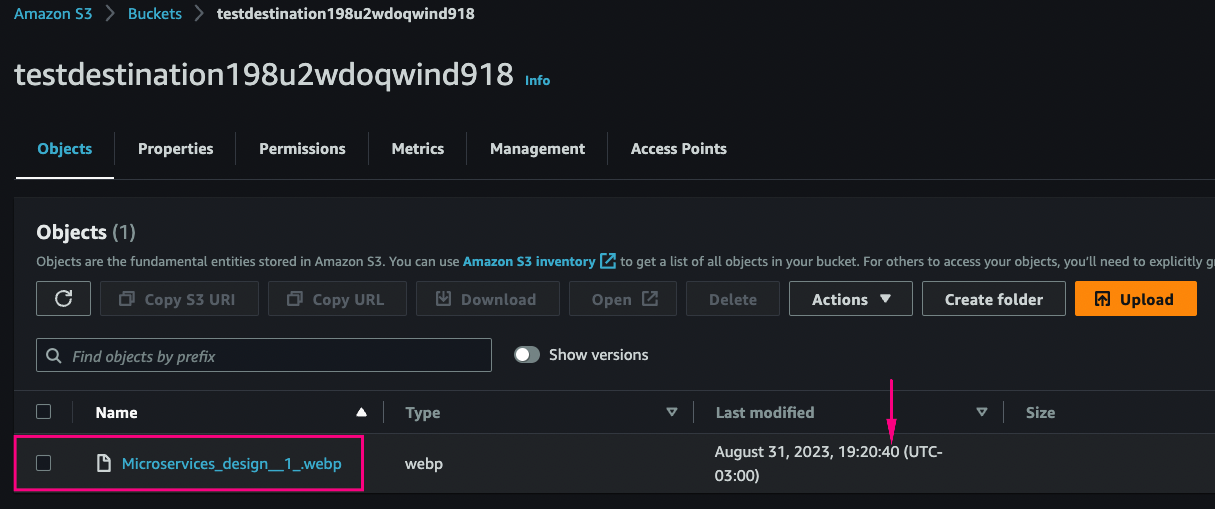
Verify that the same file you uploaded to the source bucket is present on the destination bucket
When data is replicated across several disks, data loss happens when one of those disks fails, and in the time while a new copy is being created to replace the one that just failed, another disk also fails. The probability of losing data clearly depends on how often a disk fails (called Mean Time Between Failures, or MTBF) and how long it takes to recreate that copy (called Mean Time To Recovery or MTTR). But if I gave you those numbers, would you know how to calculate the probability of data loss? I didn't, until I read this article!
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
Real scenarios and solutions
The why behind the solutions
Best practices to improve them
Subscribe for free
If you'd like to know more about me, you can find me on LinkedIn or at www.guilleojeda.com