Imagine this scenario: You successfully replicated your data to another region, so if your AWS region fails you can still access the data. However, all your servers are still down! You'd like to continue operating even in the event of a disaster.
Disaster Recovery and Business Continuity
Disasters are events that cause critical damage to our ability to operate as a business. Consider an earthquake near your datacenter (or the ones you're using in AWS), or a flood in that city (this happened to GCP in Paris in the second half of 2023). It follows that Business Continuity is the ability to continue operating (or recovering really fast) in the event of a Disaster. The big question is: How do we do that?
First, let's understand what recovering looks like, and how much data and time can we lose (yes, we lose both) in the process. There are two objectives that we need to set:
Recovery Point Objective (RPO)
The RPO is the maximum time that passes between when the data is written to the primary storage and when it's written to the backup. For periodic backups, RPO is equal to the time between backups. For example, if you take a snapshot of your database every 12 hours, your RPO is 12 hours. For continuous replication, the RPO is equal to the replication delay. For example, if you continuously replicate data from the primary storage to a secondary one, the RPO is the delay in that replication.
Data that hasn't yet been written to the backup won't be available in the event of a disaster, so you want your RPO to be as small as possible. However, minimizing it may require adopting new technologies, which means effort and money. Sometimes it's worth it, sometimes it isn't.
Different data may require different RPOs. Since the easiness of achieving a low RPO mostly depends on what technologies you use, the decision of what the RPO is for a specific set of data should be considered when selecting where to store it.
Recovery Time Objective (RTO)
The RTO is the maximum time that can pass from when a failure occurs to when you're operational again. The thing that will have the most impact on RTO is your disaster recovery strategy, which we'll see a bit further down this article. Different technologies will let you reduce the RTO within the same DR strategy, and a technology change may be a good way to reduce RTO without significantly increasing costs.
Stages of a Disaster Recovery Process
These are the three stages that a disaster recovery process goes through, always in this order.
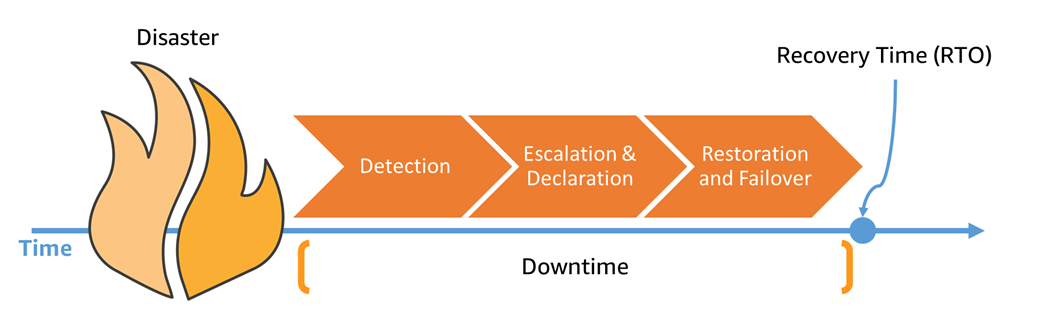
Detect
Detection is the phase between when the failure actually occurs and when you start doing something about it. The absolute worst way to learn about a failure is from a customer, so detection should be the first thing you automate. The easiest way to do so is through a health check, which is a sample request sent periodically (e.g. every 30 seconds) to your servers. For example, Application Load Balancer implements this to detect whether targets in a target group are healthy, and can raise a CloudWatch Alarm if it has no healthy targets. You can connect that alarm to SNS to receive an email when that happens, and you'd have automated detection.
Escalate and Declare
This is the phase from when the first person is notified about an event 🔥 and when the alarm 🚨 sounds and everyone is called to battle stations 🚒. It may involve manually verifying something, or it may be entirely automated. In many cases it happens after a few corrective actions have been attempted, such as rolling back a deployment.
Restore
These are the steps necessary to get a system back online. It may be the old system that we're repairing, or it may be a new copy that we're preparing. It usually involves one or several automated steps, and in some events manual intervention is needed. It ends when the system is capable of serving production traffic.
Fail over
Once we have a live system capable of serving production traffic, we need to send traffic to it. It sounds trivial, but there are several factors that make it worth being a stage on its own:
You usually want to do it gradually, to avoid crashing the new system
It may not happen instantly (for example, DNS propagation)
Sometimes this stage is triggered manually
You need to verify that it happened
You continue monitoring afterward
Disaster Recovery Strategies on AWS
The two obvious solutions to disaster recovery are:
Both work, but they're not the only ones. They're actually the two extremes of a spectrum:
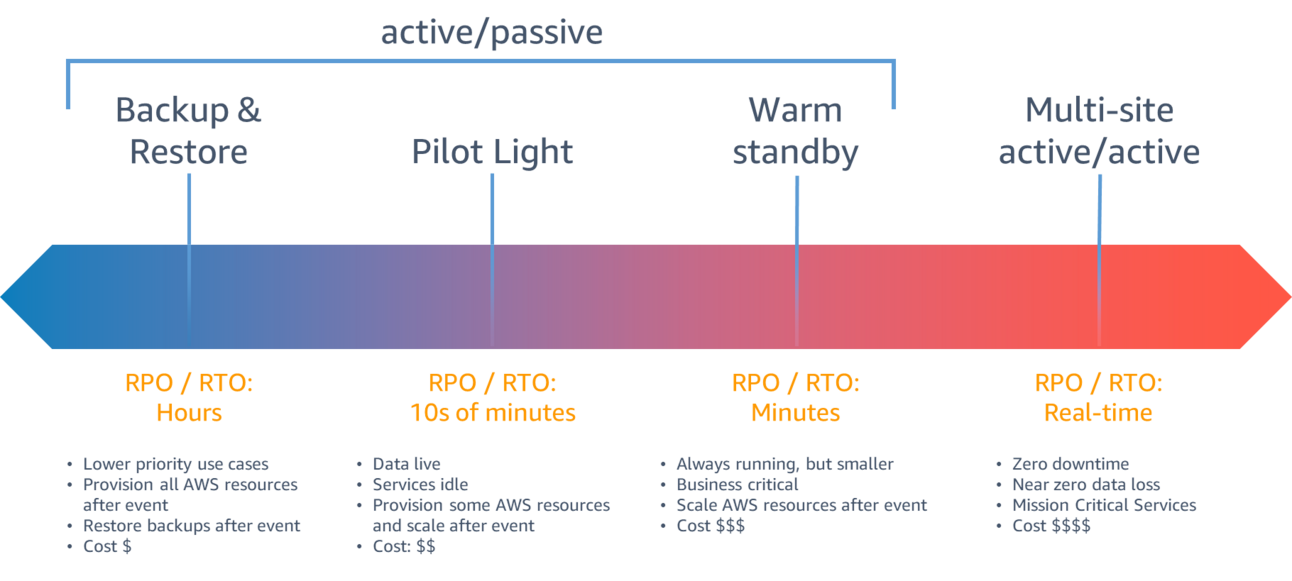
Backup and Restore
This is the simplest strategy, and the playbook is:
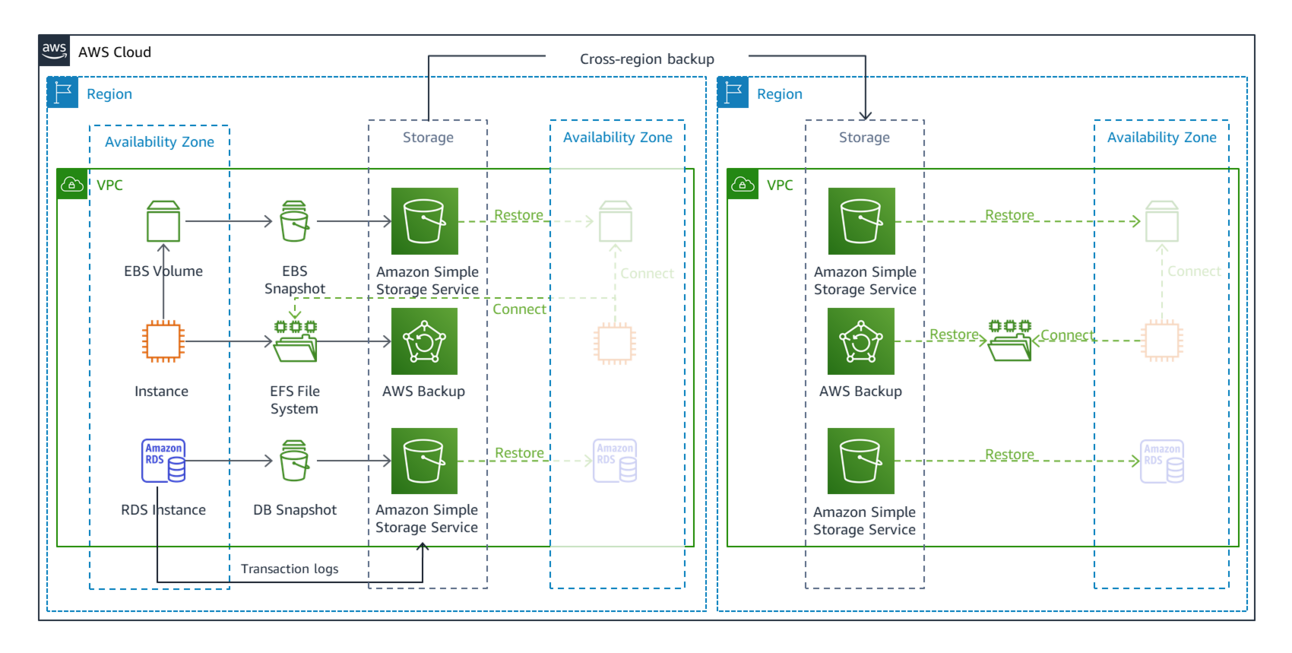
It's by far the cheapest, all you need to pay for are the backups and any other regional resources that you need to operate (e.g. KMS keys used to encrypt data). When a disaster happens, you restore from the backups and re-create everything.
I'm being purposefully broad when I say "re-create everything". I bet your infrastructure took you a long time to create. How fast can you re-create it? Can you even do it in hours or a few days, if you can't look at how you did it the first time? (Remember the original region is down).
The answer, of course, is Infrastructure as Code. It will let you launch a new stack of your infrastructure with little effort and little margin for error. That's why we (and by we I mean anyone who knows what they're doing with cloud infrastructure) insist so much on IaC.
As you're setting up your infrastructure as code, don't forget about supporting resources. For example, if your CI/CD Pipeline runs in a single AWS Region (e.g. you're using CodePipeline), you'll need to be ready to deploy it to the new region along with your production infrastructure. Other common supporting resources are values stored in Secrets Manager or SSM Parameter Store, KMS keys, VPC Endpoints, and CloudWatch Alarms configurations.
You can define all your infrastructure as code, but creating the new copy from your templates usually requires some manual actions. You need to document everything, so you're clear on what's the correct order for the different actions, what parameters to use, common errors and how to avoid or fix them, etc. If you have all of your infrastructure defined as code, this documentation won't be really large. However, it's still super important.
Finally, test everything. Don't just assume that it'll work, or you'll find out that it doesn't right in the middle of a disaster. Run periodic tests for your Disaster Recovery plan, keep the code and the documentation up to date, and keep yourself and your teams sharp.
Pilot Light
With Backup and Restore you need to create a lot of things from scratch, which takes time. Even if you cut down all the manual processes, you might spend several hours staring at your terminal or the CloudFormation console waiting for everything to create.
What's more, most of these resources aren't even that expensive! Things like an Auto Scaling Group are free (without counting the EC2 instances), an Elastic Load Balancer costs only $23/month, and VPC and subnets are free. The largest portion of your costs come from the actual capacity that you use: a large number of EC2 instances, DynamoDB tables with a high capacity, etc. But since most of them are scalable, you could keep all the scaffolding set up with capacity scaled to 0, and scale up in the event of a disaster, right?
That's the idea behind Pilot Light, and this is the basic playbook:
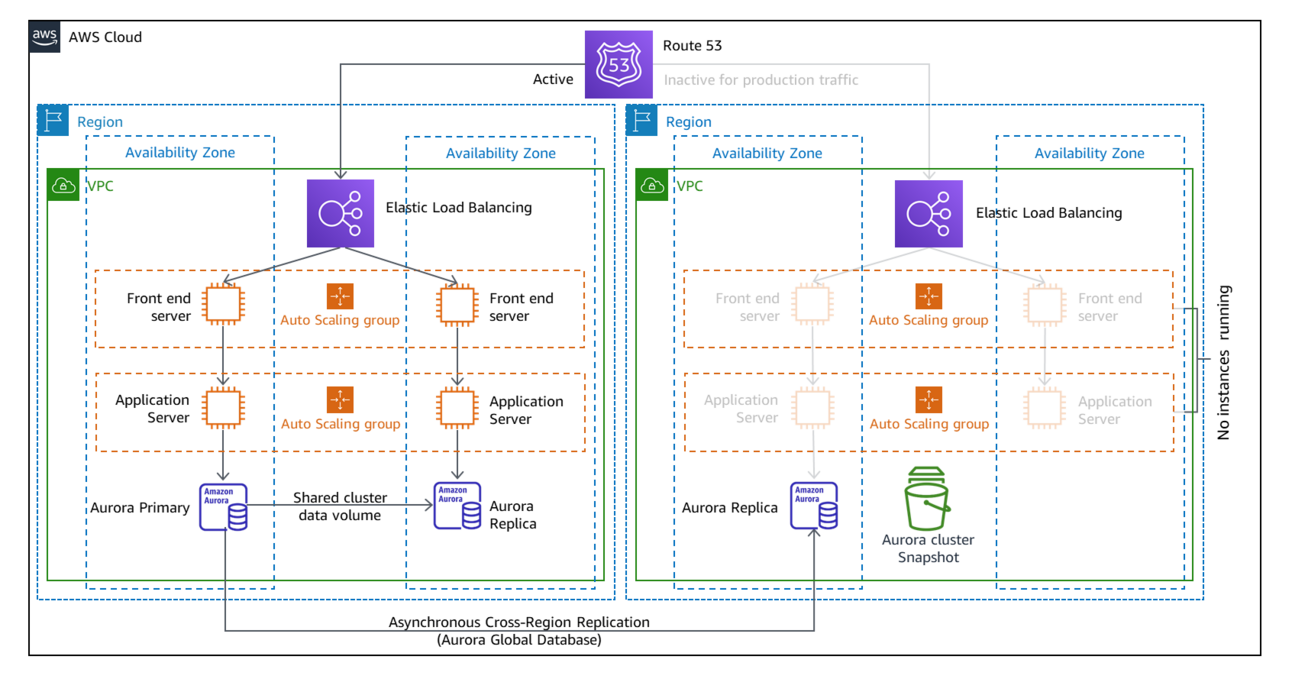
One of the things that takes the longest time to create is data stores from snapshots. For that reason, the prescriptive advice (though not a strict requirement) for Pilot Light is to keep data stores functioning, instead of just keeping the backups and restoring from them in a disaster. It is more expensive though.
Since scaling can be done automatically, the Restore stage is very easy to automate entirely when using Pilot Light. Also, since the scaling times are much shorter than creating everything from scratch, the impact of automating all manual operations will be much higher, and the resulting RTO much lower than with Backup and Restore.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
Warm Standby
The problem with Pilot Light is that, before it scales, it cannot serve any traffic at all. It works just like the pilot light in a home heater: a small flame that doesn't produce any noticeable heat, but is used to light up the main burner much faster. It's a great strategy, and your users will appreciate that the service interruption is brief, in the order of minutes. But what if you need to serve at least those users nearly immediately?
Warm Standby uses the same idea as Pilot Light, but instead of remaining at 0 capacity, it keeps some capacity available. That way, if there is a disaster you can fail over immediately and start serving a subset of users, while the rest of them wait until your infrastructure in the DR region scales up to meet the entire production demand.
Here's the playbook:
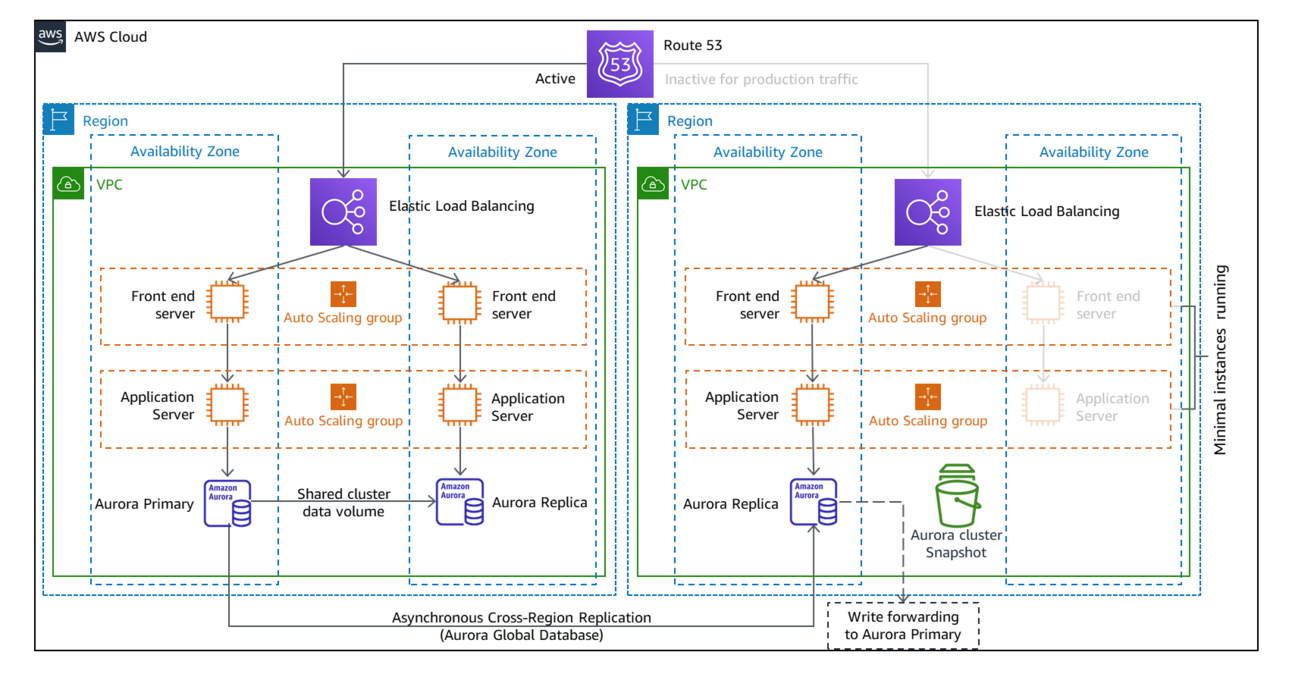
What portion of the traffic you reroute depends on how much capacity you maintain "hot" (i.e. available). This lets you do some interesting things, like setting up priorities where traffic for some critical services is rerouted and served immediately, or even for some premium users.
It also presents a challenge: How much infrastructure do you keep hot in your DR region? It could be a fixed number like 2 EC2 instances, or you could dynamically adjust this to 20% of the capacity of the primary region (just don't accidentally set it to 0 when the primary region fails!).
You'd think dynamically communicating to the DR region the current capacity or load of the primary region would be too problematic to bother with. But you should be doing it anyway! When a disaster occurs and you begin scaling up your Pilot Light or Warm Standby infrastructure, you don't want to go through all the hoops of scaling slowly from 0 or low capacity to medium, to high, to maximum. You'd rather go from wherever you are directly to 100% of the capacity you need, be it 30 EC2 instances, 4000 DynamoDB WCUs, or whatever service you're using. To do that, you need to know how much is 100%, or in other words, how much capacity the primary region was running on before it went down. Remember that once it's down you can't go check! To solve that, back up the capacity metrics to the DR region. And once you have them, it's trivial to dynamically adjust your warm standby's capacity.
You can pick any number or percentage that you want, and it's really a business decision, not a technical one. Just keep in mind that if you pick 0 you're actually using a Pilot Light strategy, and if you pick 100% it's a variation of Warm Standby called Hot Standby, where you don't need to wait until infrastructure scales before rerouting all the traffic.
An important aspect that Warm Standby introduces is the fact that all three strategies that we've seen so far are active/passive, meaning that one region (the active one) serves traffic, while the other region (the DR one, which is passive) doesn't receive any traffic. With Backup and Restore and with Pilot Light that should be obvious, since they're not able to serve any traffic. Warm Standby is able to serve some traffic, and Hot Standby is able to serve the entirety of the traffic. But even then, they don't get any traffic, and the DR region is passive.
The reason for this is that, if you allow your DR region to write data while you're using the primary region (i.e. while it isn't down), then you need to deal with distributed databases with multiple writers, which is much harder than a single writer and multiple readers. Some managed services handle this very well, but even then there are implications that might affect your application. For example, DynamoDB Global Tables handle writes in any region where the global table is set up, but they resolve conflicts with a last-writer-wins reconciliation strategy, where if two regions receive write operations for the same item at the same time (i.e. within the replication delay window), the one that was written last is the one that sticks. Not a bad solution, but you don't want to overcomplicate things if you don't have to.
Multi-site Active/Active
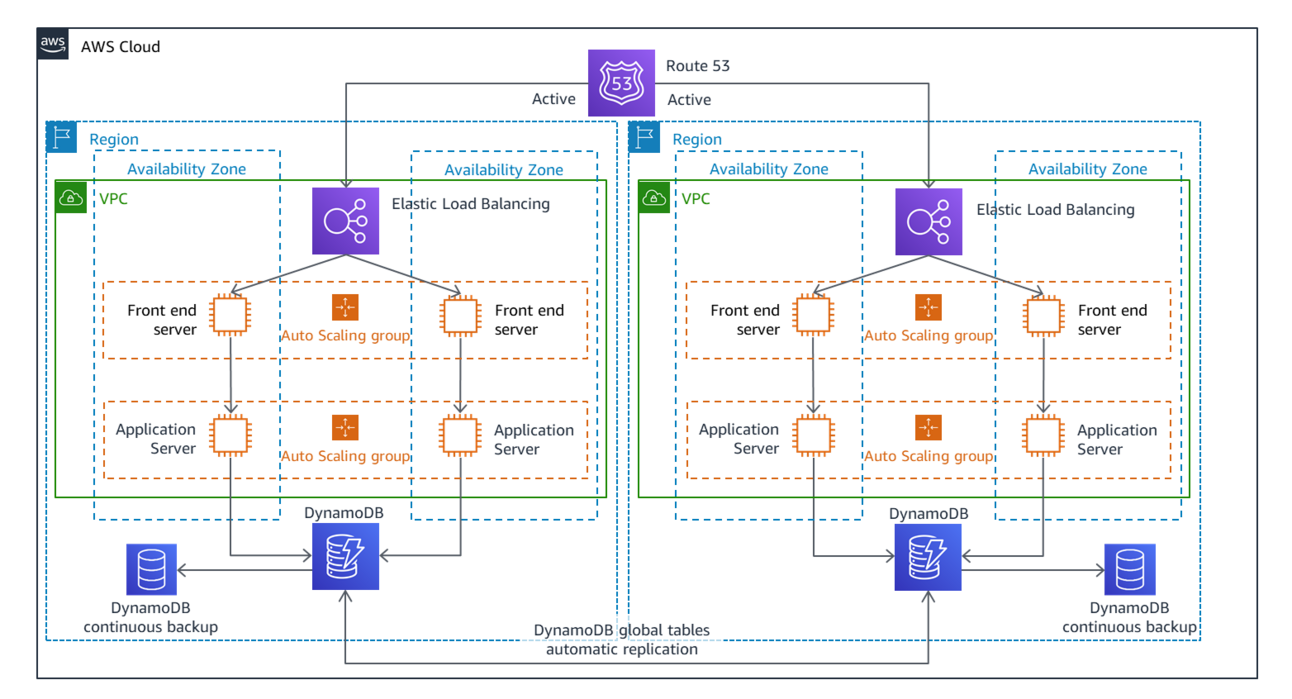
In active/passive configurations, only one region serves traffic. Active/active spreads the traffic across both regions in normal operation conditions (i.e. when there's no disaster). As mentioned in the previous paragraph, this introduces a few problems.
The main problem is the read/write pattern that you'll use. Distributed data stores with multiple write nodes can experience "contention", a term that means everything is slowed down because multiple nodes are trying to access the same data, and they need to wait for the others so they don't cause inconsistencies. Contention is one of the reasons why databases are hard.
Another problem is that you're effectively managing two identical but separate infrastructures. Suddenly it's not just a group of instances plus one of everything else (Load Balancer, VPC, etc), but two of everything.
You also need to duplicate any configuration resources, such as Lambda functions that perform automations, SSM documents, SNS topics that generate alerts, etc.
Finally, instead of using the same value for "region" in all your code and configurations, you need to use two values, and use the correct one in every case. That's more complexity, more work, more cognitive load, and more chances of mistakes or slip ups.
Overall, Multi-Site Active/Active is much harder to manage than Warm Standby, but the advantage is that losing a region feels like losing an AZ when you're running a Highly Available workload: You just lose a bit of capacity, maybe fail over a couple of things, but overall everything keeps running smoothly.
Tips for Effective Disaster Recovery on AWS
Decide on a Disaster Recovery Strategy
You can choose freely between any of the four strategies outlined on this article, or you can even choose not to do anything in the event of a disaster. There are no wrong answers, there's only tradeoffs.
To pick the best strategy for you:
Calculate how much money you'd lose per minute of downtime
If there are hits to your brand image, factor them in as well
Estimate how often these outages are likely to occur
Calculate how much each DR strategy would cost
Determine your RTO for each DR strategy
Plug everything into your calculator
Make an informed decision
"I'd rather be offline for 24 hours once every year and lose $2.000 than increase my anual AWS expenses by $10.000 to reduce that downtime" is a perfectly valid and reasonable decision, but only if you've actually run the numbers and made it consciously.
Improve Your Detection
The longer you wait to declare an outage, the longer your users have to wait until the service is restored. On the other hand, a false positive (where you declare an outage when there isn't one) will cause you to route traffic away from a region that's working, and your users will suffer from an outage that isn't there.
Improving the granularity of your metrics will let you detect anomalies faster. Cross-referencing multiple metrics will reduce your false positives without increasing your detection time. Additionally, consider partial outages, how to differentiate them from total outages, and what the response should be.
Practice, Practice, Practice
As with any complex procedure, there's a high probability that something goes wrong. When would you rather find out about it, on regular business hours when you're relaxed and awake, or at 3 am with your boss on the phone yelling about production being down and the backups not working?
Disaster Recovery involves software and procedures, and as with any software or procedures, you need to test them both. Run periodic disaster recovery drills, just like fire drills but for the prod environment. As the Google SRE book says: "If you haven’t gamed out your response to potential incidents in advance, principled incident management can go out the window in real-life situations."
One of the best things you can read on Disaster Recovery is the AWS whitepaper about Disaster Recovery. In fact, it's where I took all the images from.
Another fantastic read is the chapter about Managing incidents from the Site Reliability Engineering book (by Google). If you haven't read the whole book, you might want to do so, but chapters stand independently so you can read just this one.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
Real scenarios and solutions
The why behind the solutions
Best practices to improve them
Subscribe for free
If you'd like to know more about me, you can find me on LinkedIn or at www.guilleojeda.com





