We're building an e-commerce app with DynamoDB for the database, pretty similar to the one we built for the DynamoDB Database Design article. No need to go read that issue (though I think it came up great), here's how our database works:
Customers are stored with a Customer ID starting with c# (for example c#123) as the PK and SK.
Products are stored with a Product ID starting with p# (for example p#123) as the PK and SK, and with an attribute of type number called 'stock', which contains the available stock.
Orders are stored with an Order ID starting with o# (for example o#123) for the PK and the Product ID as the SK.
When an item is purchased, we need to check that the Product is in stock, decrease the stock by 1 and create a new Order.
Payment, shipping and any other concerns are magically handled by the power of "that's out of scope for this issue" and "it's left as an exercise for the reader".
There are more attributes in all entities, but let's ignore them.
We're going to use the following AWS services:
- DynamoDB: A NoSQL database that supports ACID transactions, just like any SQL-based database.
Before Implementing DynamoDB Transactions
We need to read the value of stock and update it atomically. Atomicity is a property of a set of operations, where that set of operations can't be divided: it's either applied in full, or not at all. If we just ran the GetItem and PutItem actions separately, we could have a case where two customers are buying the last item in stock for that product, our scalable backend processes both requests simultaneously, and the events go down like this:
Customer123 clicks Buy
Customer456 clicks Buy
Instance1 receives request from Customer123
Instance1 executes GetItem for Product111, receives a stock value of 1, continues with the purchase
Instance2 receives request from Customer456
Instance2 executes GetItem for Product111, receives a stock value of 1, continues with the purchase
Instance1 executes PutItem for Product111, sets stock to 0
Instance2 executes PutItem for Product111, sets stock to 0
Instance1 executes PutItem for Order0046
Instance1 receives a success, returns a success to the frontend.
Instance2 executes PutItem for Order0047
Instance2 receives a success, returns a success to the frontend.
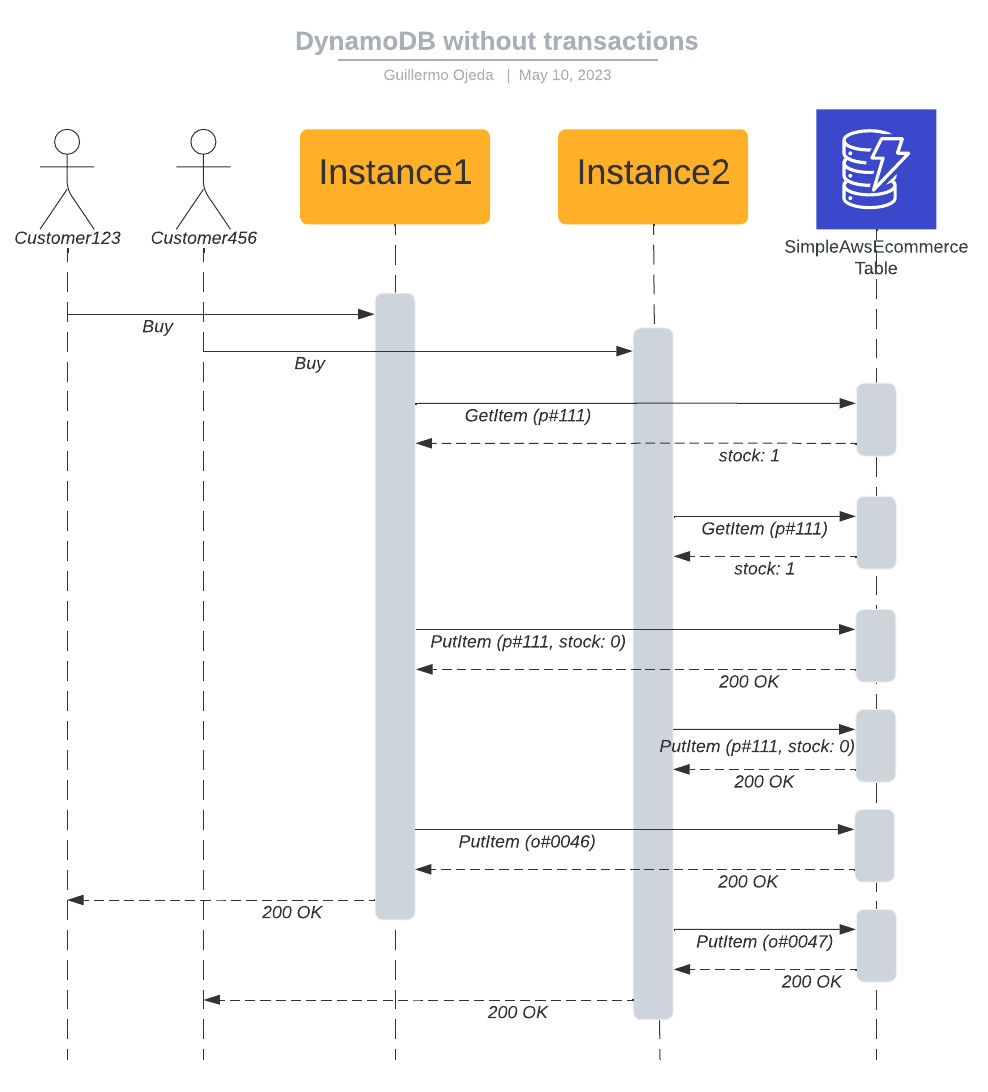
The data doesn't look corrupted, right? Stock for Product111 is 0 (it could end up being -1, depends on how you write the code), both orders are created, you received the money for both orders (out of scope for this issue), and both customers are happily awaiting their product. You go to the warehouse to dispatch both products, and find that you only have one in stock. Where did things go wrong?
Steps to Implement DynamoDB Transactions
The problem is that steps 4 and 7 were executed separately, and Instance2 got to read the stock of Product111 (step 6) in between them, and made the decision to continue with the purchase based on a value that hadn't been updated yet, but should have. Steps 4 and 7 need to happen atomically, in a transaction.
Install the AWS SDK
First, install the packages from the AWS SDK V3 for JavaScript:
npm install @aws-sdk/client-dynamodb @aws-sdk/lib-dynamodb
Update the Code to Use Transactions
This is the code in Node.js to run the steps as a transaction (you should add this to the code imaginary you already has for the service):
const { DynamoDBClient } = require('@aws-sdk/client-dynamodb');
const { DynamoDBDocumentClient } = require('@aws-sdk/lib-dynamodb');
const dynamoDBClient = new DynamoDBClient({ region: 'us-east-1' });
const dynamodb = DynamoDBDocumentClient.from(dynamoDBClient);
const newOrderId = 'o#123'
const productId = 'p#111'
const customerId = 'c#123'
const transactItems = {
TransactItems: [
{
ConditionCheck: {
TableName: 'SimpleAwsEcommerce',
Key: { id: productId },
ConditionExpression: 'stock > :zero',
ExpressionAttributeValues: {
':zero': 0
}
}
},
{
Update: {
TableName: 'SimpleAwsEcommerce',
Key: { id: productId },
UpdateExpression: 'SET stock = stock - :one',
ExpressionAttributeValues: {
':one': 1
}
}
},
{
Put: {
TableName: 'SimpleAwsEcommerce',
Item: {
id: newOrderId,
customerId: customerId,
productId: productId
}
}
}
]
};
const executeTransaction = async () => {
try {
const data = await dynamodb.transactWrite(transactItems);
console.log('Transaction succeeded:', JSON.stringify(data, null, 2));
} catch (error) {
console.error('Transaction failed:', JSON.stringify(error, null, 2));
}
};
executeTransaction();
After Implementing DynamoDB Transactions
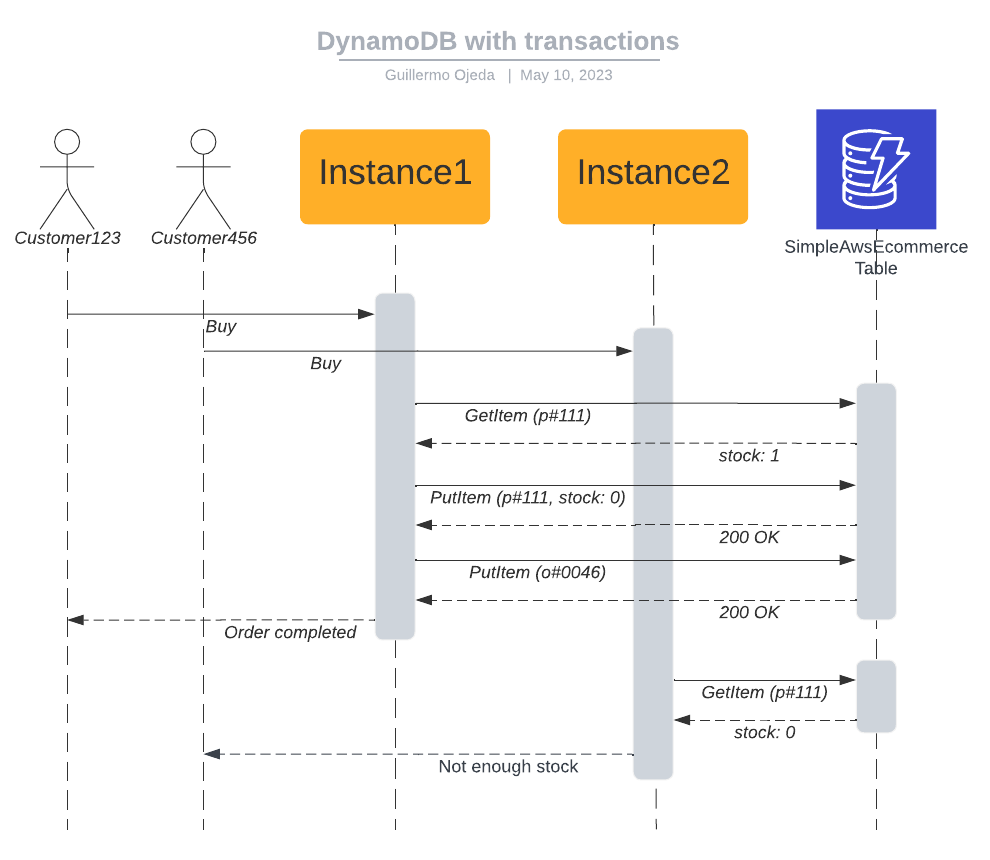
Here's how things may happen with these changes, if both customers click Buy at the same time:
Customer123 clicks Buy
Customer456 clicks Buy
Instance1 receives request from Customer123
Instance2 receives request from Customer456
Instance1 executes a transaction:
ConditionCheck for Product111, stock is greater than 0 (actual value is 1)
PutItem for Product111, set stock to 0
PutItem for Order0046
Transaction succeeds, it's committed.
Instance1 receives a success, returns a success to the frontend.
Instance2 executes a transaction:
ConditionCheck for Product111, stock is not greater than 0 (actual value is 0)
Transaction fails, it's aborted.
Instance2 receives an error, returns an error to the frontend.
Overview of DynamoDB
DynamoDB is so scalable because it's actually a distributed database, where you're presented with a single resource called Table, but behind the scenes there's multiple nodes that store the data and process queries. Data is partitioned using the Partition Key, which is part of the Primary Key (the other part is the Sort Key).
DynamoDB is highly available (meaning it can continue working if an Availability Zone goes down) because each partition is stored in 3 nodes, each in a separate Availability Zone. This is the "secret" behind DynamoDB's availability and durability. You don't need to know this to use DynamoDB effectively, but now that you do, you see that transactions in DynamoDB are actually distributed transactions.
How Transactions Work in DynamoDB
Two-Phase Commit
DynamoDB implements distributed transactions using Two-Phase Commit (2PC). This strategy is pretty simple: All nodes are requested to evaluate the transaction to determine whether they're capable of executing it, and only after all nodes report that they're able to successfully execute their part, the central controller sends the order to commit the transaction, and each node does the actual writing, affecting the actual data. For this reason, all operations done in a DynamoDB transaction consume twice as much capacity.
Itempotency
DynamoDB transactions are idempotent. They're identified by an attribute called ClientRequestToken, which the DynamoDB SDK includes automatically on any transactions. If you use the TransactReadItems API or TransactWriteItems API without the SDK, you'll need to include it to achieve transaction idempotency.
Isolation
Transaction isolation (the I in ACID) is achieved through optimistic concurrency control. This means that multiple DynamoDB transactions can be executed concurrently, but if DynamoDB detects a conflict, one of the transactions will be rolled back and the caller will need to retry the transaction.
Transactions on Multiple Tables
DynamoDB Transactions can span multiple tables, but they can't be performed on indexes. Also, propagation of the data to Global Secondary Indexes and DynamoDB Streams always happens after the transaction, and isn't part of it.
Pricing for DynamoDB Transactions
There is no direct cost for using transactions. However, all operations performed on DynamoDB as part of a transactions will consume double the amount of capacity units as they regularly would. Write and delete operations consume write capacity, and any condition expression consumes read capacity. This extra capacity is only consumed for the operations on the table, the read and write capacity consumed for updating secondary indexes and for DynamoDB Streams isn't affected. When working with DynamoDB On-Demand Mode, Request Units are doubled, just like Capacity Units.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
DynamoDB vs SQL databases
The whole point of this article and the others I've written about DynamoDB is that SQL databases shouldn't be your default. I've shown you that DynamoDB can handle an e-commerce store just fine, including ACID-compliant transactions. That's because for an e-commerce, and in fact for 95% of the applications we write, we can predict data access patterns. When we can do that, we can optimize the structure and relations of a NoSQL database like DynamoDB and have it perform much better than a relational database for those known and predicted access patterns.
The use case for SQL databases is unknown access patterns! And those come from either giving the user a lot of freedom (which might be a mistake, or might be a core feature of your application), or from doing analytics and ad-hoc queries. In those cases, definitely go for relational databases. Otherwise, see if you can solve it with a NoSQL database like DynamoDB. It'll be much cheaper, and it will scale much better. I'll make one concession though: If all your dev team knows is SQL databases, just go with that unless you have a really strong reason not to.
Using SQL in DynamoDB
This is gonna blow your mind: You can actually query DynamoDB using SQL! Or more specifically, a SQL-compatible language called PartiQL. Amazon developed PartiQL as an internal tool, and it was made generally available by AWS. It can be used on SQL databases, semi-structured data, or NoSQL databases, so long as the engine supports it.
With PartiQL you could theoretically change your Postgres database for a DynamoDB database without rewriting any queries. In reality, you need to consider all of these points:
Why are you even changing? It's not going to be easy.
How are you going to migrate all the data?
You need to make sure no queries are triggering a Scan in DynamoDB, because we know those are slow and very expensive. You can use an IAM policy to deny full-table Scans.
Again, why are you even changing?
I'm not saying there isn't a good reason to change, but I'm going to assume it's not worth the effort, and you'll have to prove me otherwise. Remember that replicating the data somewhere else for a different access pattern is a perfectly valid strategy (in fact, that's exactly how DynamoDB GSIs work). We'll discuss it further in a future issue.
Are there any limitations to using transactions in DynamoDB?
Yes, there are some limitations to using transactions in DynamoDB. Transactions are limited to a maximum of 100 unique items and the total data size within a transaction cannot exceed 4 MB. Additionally, transactions cannot operate on tables with global secondary indexes that have projected attributes.
Best Practices
Operational Excellence
Monitor transaction latencies: Monitor latencies of your DynamoDB transactions to identify performance bottlenecks and address them. Use CloudWatch metrics and AWS X-Ray to collect and analyze performance data.
Error handling and retries: Handle errors and implement exponential backoff with jitter for retries in case of transaction conflicts.
Security
- Fine-grained access control: Assign an IAM Role to your backend with an IAM Policy that only allows the specific actions that it needs to perform, only on the specific tables that it needs to access. You can even do this per record and per attribute. This is least privilege.
Reliability
- Consider a Global Table: You can make your DynamoDB table multi-region using a Global Table. Making the rest of your app multi-region is more complicated than that, but at least the DynamoDB part is easy.
- Optimize provisioned throughput: If you're using Provisioned Mode, you'll need to set your Read and Write Capacity Units appropriately. You can also set them to auto-scale, but it's not instantaneous. Remember the article on using SQS to throttle writes.
Cost Optimization
- Optimize transaction sizes: Minimize the number of items and attributes involved in a transaction to reduce consumed read and write capacity units. Remember that transactions consume twice as much capacity, so optimizing the operations in a transaction is doubly important.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
Real scenarios and solutions
The why behind the solutions
Best practices to improve them
Subscribe for free
If you'd like to know more about me, you can find me on LinkedIn or at www.guilleojeda.com





