What Is a Pod in Kubernetes?
A Kubernetes pod is the basic execution unit of a Kubernetes application. Think of it as a unique environment where your application runs, encapsulating one or more application containers and shared storage/network resources. Kubernetes has a lot of concepts that encapsulate services, endpoints and other entities, but in the end a pod is where your code is running.
Difference between Kubernetes Pods and Containers
Conceptually, a pod can be compared to a Container, especially when comparing Kubernetes with Docker Compose. Pods do fulfill in Kubernetes the same role that containers fulfill in Docker Compose, but a pod is actually a layer of abstraction over one or more containers, with associated networking and storage configurations. Pods can contain several containers, but the best practice is to have a single main container running the application code, and zero or more support containers that provide the application with additional features like logging, monitoring and networking in a decoupled way. This pattern is called Sidecar, and these support containers are called sidecar containers.
Difference between Kubernetes Pods and Nodes
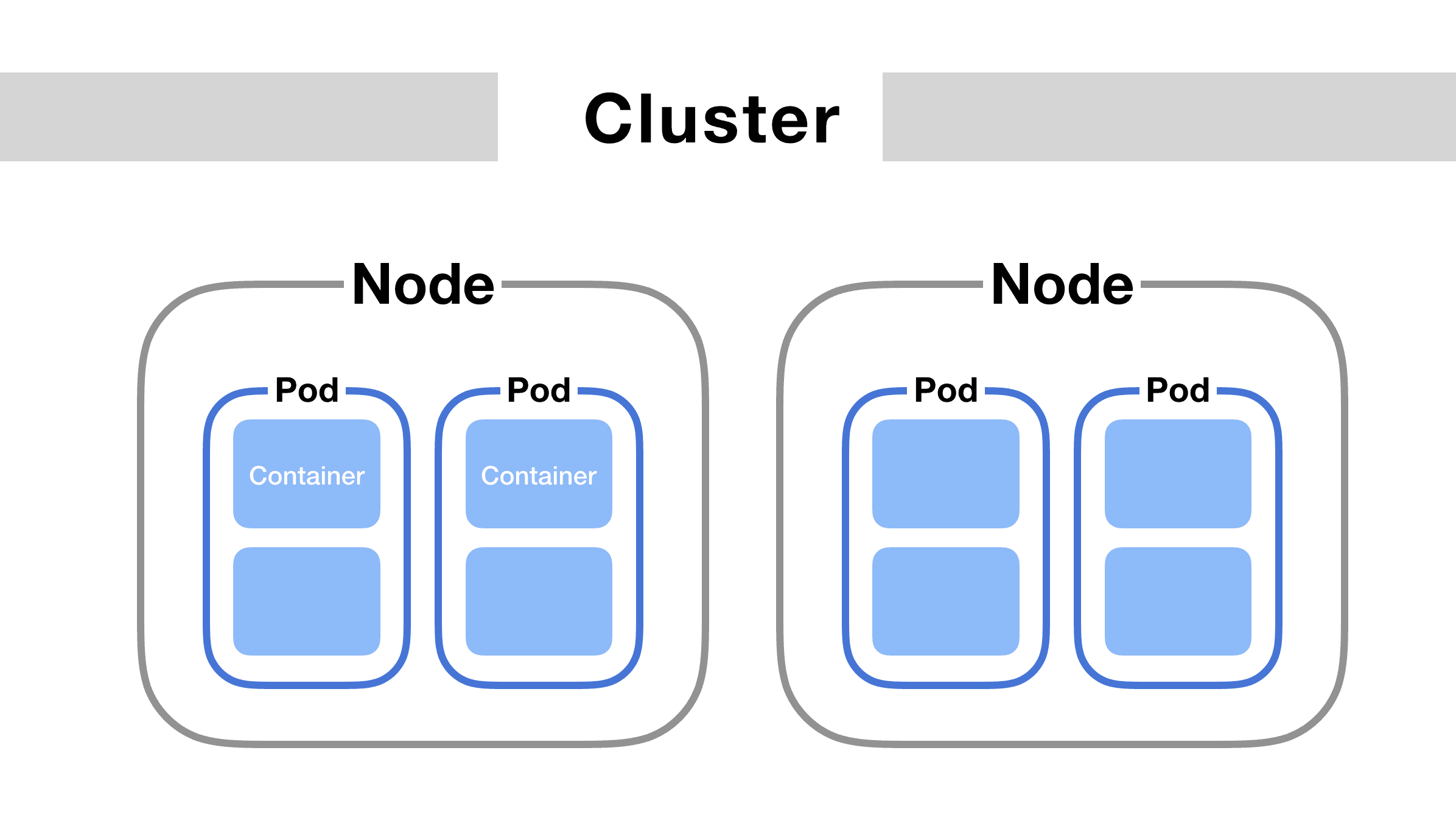
A node is a worker in Kubernetes, which is where pods run. Nodes can be virtual, such as AWS EC2 instances, or physical computer servers. Pods are assigned to nodes, and they run on those nodes, consuming the capacity that the node provides to the cluster. Pods aren't explicitly bound to nodes, they are assigned by the Kubernetes Control Plane, and can be moved from one node to another if necessary.
Difference between Kubernetes Pods and Cluster
A cluster is essentially a group of nodes providing capacity, a group of pods running applications, and other configurations such as services or ingress controllers, all of this managed by the Kubernetes Control Plane. Conceptually, pods can be thought of as the way that Kubernetes runs applications.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
How Do Kubernetes Pods Work?
Pods are a layer of abstraction on top of a main container with our code, and zero or more support or sidecar containers. In addition to the containers, pod have an identity on the Kubernetes cluster, and several configurations.
Pod Lifecycle
Pods can go through several stages in their lifecycle:
Pending: The pod is accepted by the system, but one or more of the containers is not set up and running.
Running: The pod is bound to a node, and all of its containers are created.
Succeeded: All containers in the pod have terminated successfully and will not restart. The pod is no longer bound to a node and consuming resources.
Failed: At least one container in the pod has terminated in failure. The pod is no longer bound to a node and consuming resources.
Unknown: When the state is inexplicable due to some issues in communicating with the pod's host node. When a node fails to report its status to the Kubernetes Control Plane, pods that were running in that node enter the Unknown state.
How Pods manage multiple containers
A pod can encapsulate multiple containers, ensuring they share the same storage and network namespace. This lets us couple application helper processes with the primary application, and avoid dealing with network configurations between them. Containers that run in the same pod share the local network and storage. This is often used for sidecar containers, such as Logging, Monitoring or Network configurations.
For example, this is how you configure a pod with multiple containers:
apiVersion: v1
kind: Pod
metadata:
name: simple-pod
spec:
containers:
- name: main-app
image: main-app:v1
- name: helper-logger
image: logger-helper:v1
Working with Pods in Kubernetes
Kubernetes is a complex platform, and running production workloads requires a bit more knowledge than just defining a pod with a container. Here are some additional concepts that you need to understand in order to manage pods effectively.
Pod update and replacement
Directly updating a running pod isn’t a good practice, since it breaks the assumption of pod immutability (essentially the same as container immutability). In fact, Kubernetes enforces this immutability at the pod level, meaning it rejects updates to pods. Instead, you should deploy a new version of the pod and gracefully redirect traffic to the newer version. If this deployment is done gradually, replacing one pod at a time (relevant when you're running several pods for the same application), this is called a Rolling Update. If you deploy an entire new set of pods, redirect traffic to them, verify that they work and only then terminate the old pods, this is called a Blue/Green Deployment.
When you create a Deployment, which contains a group of Pods, you can define the update strategy. For example, here's how to define a RollingUpdate strategy:
apiVersion: apps/v1
kind: Deployment
metadata:
name: rolling-deployment
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
...
Storage in Pods
Pods only have ephemeral storage, implemented through working memory. Persistent storage can be created using a Persistent Volume, and associated to a pod through a Persistent Volume Claim. Conceptually, persistent volumes can be compared to nodes: they make underlying resources (storage in this case, not compute) available to the Kubernetes cluster. Persistent Volume Claims reserve those available resources for usage by a pod, to which they're associated. These persistent volume claims can be associated to the containers inside the pod as volumes, and accessed as part of the local file system of the container. Importantly, they can be shared by all containers in the pod, allowing file-based inter-container communication in the same pod. Logging sidecar containers usually use this to read the logs from the main container and export them to an external log aggregator like AWS CloudWatch Logs.
This is how you can define a Persistent Volume Claim and associate it to a container in a pod, as a volume:
apiVersion: v1
kind: Pod
metadata:
name: example-storage-pod
spec:
containers:
- name: app
image: simple-app:v2
volumeMounts:
- mountPath: /app/data
name: app-data
volumes:
- name: app-data
persistentVolumeClaim:
claimName: simplepvc
Pod networking
Each pod is allocated a unique IP address across the entire cluster, which can be addressed from inside the cluster. You can also define Services, which let you address homogeneous groups of pods (typically a Deployment) through a single IP address or private DNS name, and load balance traffic across those pods. Ingresses can also be defined, to expose a service to outside the cluster through an Ingress Controller.
Next steps
Kubernetes is a really powerful platform, but that power comes with a significant degree of complexity. Pods are just the starting point, but understanding how they work is necessary to get a grip on the abstractions and configurations that Kubernetes uses on top of pods to deploy production-grade workloads. Soon I'll be writing a follow-up article with a deep dive into Kubernetes Networking, including services and ingress controllers.
If you'd like to continue learning about Kubernetes, I suggest my guide on How to deploy a Node.js app on Kubernetes on EKS.
Stop copying cloud solutions, start understanding them. Join over 45,000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
Real scenarios and solutions
The why behind the solutions
Best practices to improve them
Subscribe for free
If you'd like to know more about me, you can find me on LinkedIn or at www.guilleojeda.com